项目
博客
归档
资源链接
关于我
项目
博客
归档
资源链接
关于我
初探数据采集方案:Python实现知嘟嘟平台专利查询与数据解析
2024-09-12
·
YuanJs
·
原创
·
Python
·
本文共 1,153个字,预计阅读需要 4分钟。
### 引言 在数字化时代,数据的价值不言而喻。无论是企业决策、市场研究还是个人兴趣探索,数据采集都是获取信息的第一步。本文将详细讲述使用Python对知嘟嘟平台进行专利数据查询的全过程,涵盖从数据请求、代理使用、到网页的解析与结构化处理,最终获取需要的专利信息。通过一个真实的案例演示,本文将带你深入了解数据采集的全流程。 ### 数据采集方案概述 数据采集的核心是通过编程手段从指定的网站或平台获取结构化或非结构化数据。这一过程通常涉及三大步骤: 1. 发送请求并获取网页数据:通过HTTP请求(如GET、POST等)访问目标网站或平台。 2. 解析网页内容:将获取到的网页转换为便于处理的结构,如HTML、XML等。 3. 提取所需信息:利用解析工具从网页中提取出有效的数据信息。 我们将通过知嘟嘟专利平台的查询实例,来演示如何完成整个数据采集流程。 ### 具体案例:知嘟嘟平台专利查询 #### 环境准备 1. 基于Python进行编码,需安装Python环境: - 下载地址:https://www.python.org/downloads/ - 安装后查询版本:`python --version` , 指定版本 3.9.13+ 2. 安装python编辑器: PyCharm - 下载地址:https://www.jetbrains.com/pycharm/download/ - 配置镜像源:File > Settings > Project > Python Interpreter > + > Manage Repositories ,添加镜像源: - 阿里云:https://mirrors.aliyun.com/pypi/simple/ - 清华云:https://pypi.tuna.tsinghua.edu.cn/simple/ 3. 依赖库安装`requirements.txt`: ```python # 代理 PySocks==1.7.1 # 网页请求 requests==2.31.0, # 网页解析 lxml==4.9.3 bs4==0.0.2 ``` #### 使用Python `requests` 进行专利查询 知嘟嘟平台提供了一个丰富的专利查询的平台。可以通过专利号进行搜索,查询专利详情。 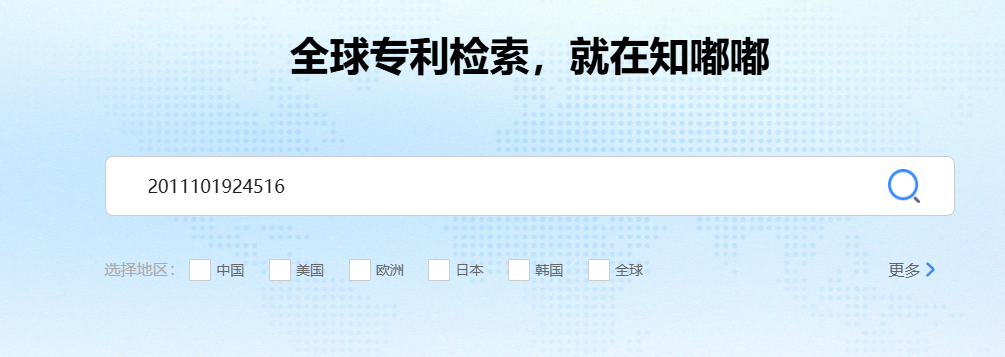 为了自动化执行查询操作,我们可以使用Python中的`requests`库向该平台发送请求,获取相应的网页数据。通过浏览器查询到访问地址 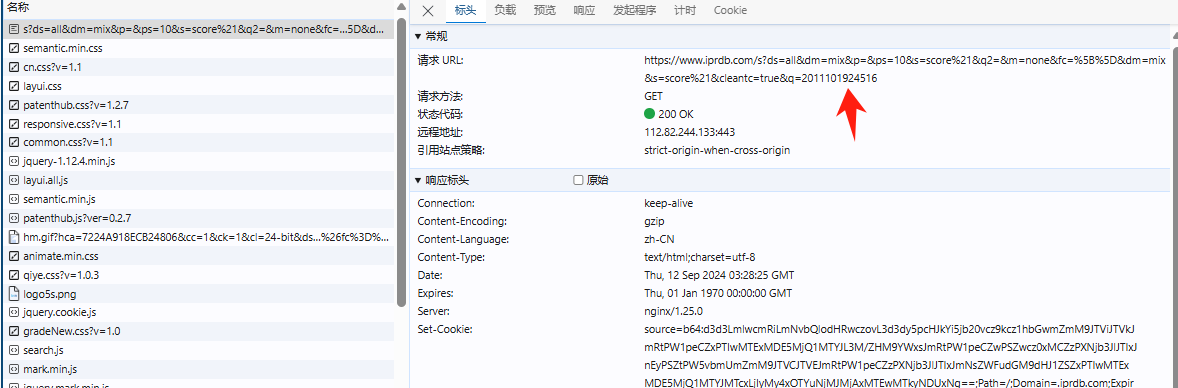 以下是实现过程: ```python import time import socket import socks import requests # 访问地址 request_url = 'https://www.iprdb.com/s?ds=all&fc=%5B%5D&dm=mix&q=' # 设置socks5代理地址及端口 socks.set_default_proxy(socks.SOCKS5, "127.0.0.1", 10808) # 设置socks5代理地址、端口、用户、密码 # socks.set_default_proxy(socks.SOCKS5, "127.0.0.1", 1080, username="root", password="root") socket.socket = socks.socksocket # 要查询的专利号 pn = '2011101924516' print(f'start query {pn} ... ') response = requests.get(request_url + pn) # 打印响应内容 print(response.text) ``` 在这个代码段中,我们通过发送GET请求获取知嘟嘟平台上的专利查询结果。为了应对一些平台的反爬虫机制,我们同步使用了代理服务,这样可以有效避免因频繁访问导致IP被封禁。 #### 将网页数据转换为XML格式 通过访问网页查询的页面数据可以看出是一个表格数据,因此,需要对响应的网页数据做处理。 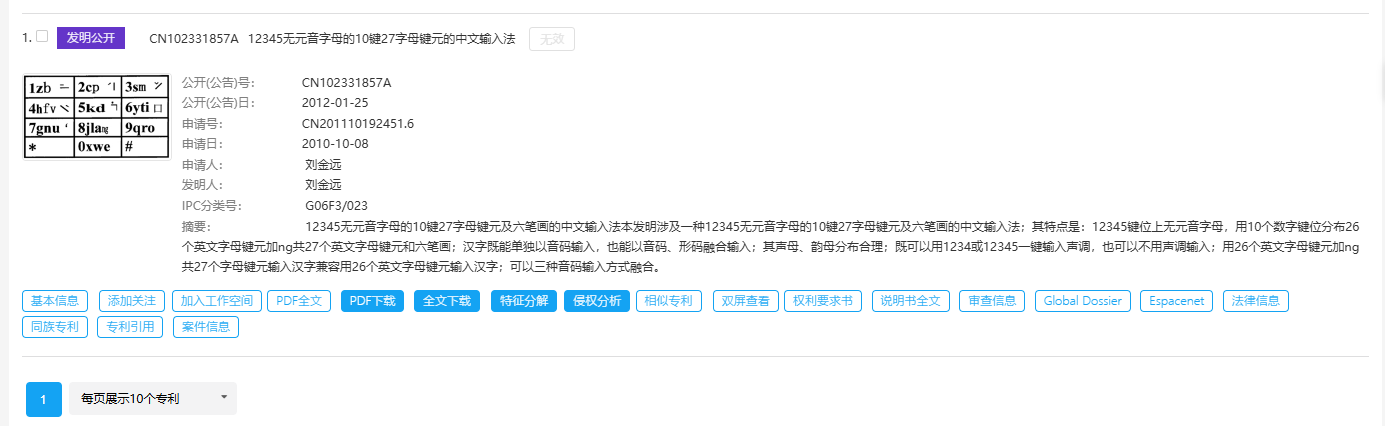 接下来,我们需要将获取到的网页数据进行结构化处理。为了更好地解析数据,我们会使用`lxml`库中的`etree`模块将HTML转换为XML结构。这样可以更加清晰地处理和提取我们需要的专利数据。 ```python from lxml import etree # 将响应数据response进行转换为xml html = etree.HTML(response.text) ul = html.xpath('//*[@id="mode_1"]/ul') size = len(ul) rsp = {} for index, li in enumerate(ul): print(f'下标:{index}, 数据{li} ') ``` 通过这个步骤,原始的HTML内容被转化为XML结构,使我们后续的解析操作更加方便。这种转换不仅提高了数据处理的灵活性,还使我们能够以更规范的方式从网页中提取信息。 #### 使用 `BeautifulSoup` 解析网页数据 根据网页可以看到结构 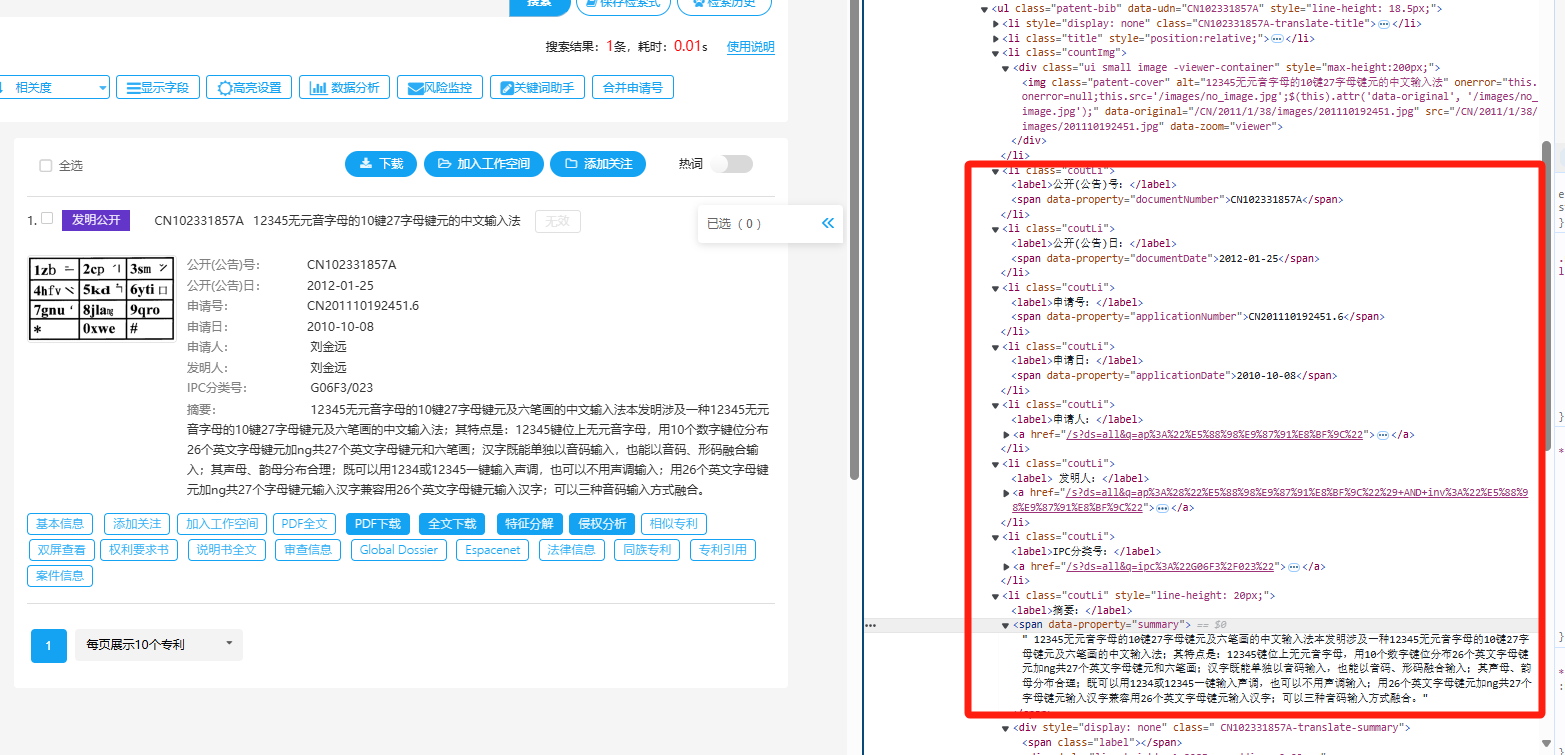 在获取到XML结构的网页内容后,我们需要进一步解析并提取具体的专利数据。`BeautifulSoup` 是一个强大的网页解析库,能够帮助我们从复杂的HTML或XML结构中迅速找到所需的数据信息。以下是如何利用`BeautifulSoup`提取专利列表: ```python from bs4 import BeautifulSoup a_n = BeautifulSoup(etree.tostring(li, encoding="unicode"), 'html.parser') # 专利号 aN = a_n.find("span", {"data-property": "applicationNumber"}).get_text().replace('CN', '').replace('.', '') title = a_n.find("span", {"data-property": "title"}).get_text() status_tags = a_n.find_all("a", class_=lambda value: value and value.startswith("ui patent-tag horizontal basic label")) documentNumber = a_n.find("span", {"data-property": "documentNumber"}).get_text() documentDate = a_n.find("span", {"data-property": "documentDate"}).get_text() applicationDate = a_n.find("span", {"data-property": "applicationDate"}).get_text() applicant = a_n.find("span", {"data-property": "applicant"}).get_text() inventor = a_n.find("span", {"data-property": "inventor"}).get_text() summary = a_n.find("span", {"data-property": "summary"}).get_text().replace('\n', '').replace(' ', '') ``` 在这个过程中,我们首先通过`BeautifulSoup`解析XML数据,并找到包含专利信息的特定HTML元素。,提取出每个专利的名称和链接。这使得我们可以轻松获取并展示知嘟嘟平台上的专利信息。 #### 注意 当我们在传入不同的专利号搜索时,有时会搜索不到。 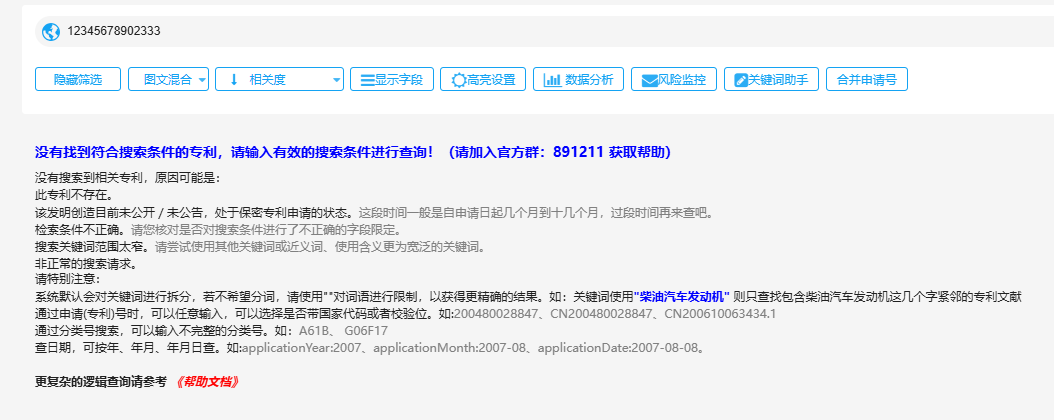 如果在访问过于频繁时,也会存在搜索不到,此时需要判读特殊处理,代码如下: ```python # 将响应数据response进行匹配判读 if "您访问过于频繁" in response.text: print('您访问过于频繁 ...') return None elif '没有找到符合搜索条件的专利' in response.text: print(f'{pn} 没有找到符合搜索条件的专利 ...') return '未查询到专利结果' ``` 同步对响应数据进行判读,有效的避免了数据解析错误,同时,在BeautifulSoup解析每个数据的时候,要异常捕获,防止每个专利数据结构不一致导致某个参数解析报错; ```python try: title = a_n.find("span", {"data-property": "title"}).get_text() except Exception as e: print(f'专利号{pn}无标题') ``` #### 完整代码 ```python import time from datetime import datetime from lxml import etree import socket import socks import requests from bs4 import BeautifulSoup # 访问地址 request_url = 'https://www.iprdb.com/s?ds=all&fc=%5B%5D&dm=mix&q=' # 响应字段名称 cot = ["applicationNumber", "title", "type", "documentNumber", "documentDate", "applicationDate", "applicant", "inventor", "summary"] # 设置socks5代理地址及端口 socks.set_default_proxy(socks.SOCKS5, "127.0.0.1", 10808) # 设置socks5代理地址、端口、用户、密码 # socks.set_default_proxy(socks.SOCKS5, "127.0.0.1", 1080, username="root", password="root") socket.socket = socks.socksocket # 获取专利详细数据 def query_info(pn): print(f'start query {pn} ... ') try: resp = requests.get(request_url + pn).text if "您访问过于频繁" in resp: print('您访问过于频繁 ...') return None elif '没有找到符合搜索条件的专利' in resp: print(f'{pn} 没有找到符合搜索条件的专利 ...') return {cot[0]: pn, cot[1]: '未查询到专利结果'} html = etree.HTML(resp) ul = html.xpath('//*[@id="mode_1"]/ul') size = len(ul) rsp = {} for index, li in enumerate(ul): a_n = BeautifulSoup(etree.tostring(li, encoding="unicode"), 'html.parser') aN = a_n.find("span", {"data-property": "applicationNumber"}).get_text().replace('CN', '').replace('.', '') if aN != pn: print(f'模糊搜索专利号不匹配: {pn} != {aN}') if index + 1 == size and len(rsp) == 0: return {cot[0]: pn, cot[1]: '未查询到专利结果'} continue rsp[cot[0]] = aN try: rsp[cot[1]] = a_n.find("span", {"data-property": "title"}).get_text() except Exception as e: print(f'专利号{pn}无标题') try: rsp[cot[2]] = types[0] status_tags = a_n.find_all("a", class_=lambda value: value and value.startswith("ui patent-tag horizontal basic label")) for tag in status_tags: if tag.text.strip() == '有权': rsp[cot[2]] = tag.text break except Exception as e: print(f'专利号{pn}获取状态异常') try: rsp[cot[3]] = a_n.find("span", {"data-property": "documentNumber"}).get_text() except Exception as e: print(f'专利号{pn}获取无documentNumber') try: rsp[cot[4]] = a_n.find("span", {"data-property": "documentDate"}).get_text() except Exception as e: print(f'专利号{pn}获取无documentDate') try: rsp[cot[5]] = a_n.find("span", {"data-property": "applicationDate"}).get_text() except Exception as e: print(f'专利号{pn}获取无applicationDate') try: rsp[cot[6]] = a_n.find("span", {"data-property": "applicant"}).get_text() except Exception as e: print(f'专利号{pn}获取无applicant') try: rsp[cot[7]] = a_n.find("span", {"data-property": "inventor"}).get_text() except Exception as e: print(f'专利号{pn}获取无inventor') try: rsp[cot[8]] = a_n.find("span", {"data-property": "summary"}).get_text().replace('\n', '').replace(' ', '') except Exception as e: print(f'专利号{pn}获取无summary') return rsp except Exception as e: print(f'专利号{pn},调用接口不通') print(e) return None if __name__ == '__main__': print(query_info(sn='2011101924516')) ``` ### 案例总结 通过这个案例,我们完成了从发送HTTP请求获取网页数据、将HTML转化为XML结构、到利用`BeautifulSoup`解析和提取专利信息的全过程。整个数据采集方案以Python为基础,结合了`requests`、`lxml`和`BeautifulSoup`等强大的工具库,极大地提高了数据获取的效率和准确性。 ### 结语 自动化的数据采集在信息时代具有重要的价值。本文通过对知嘟嘟平台的专利查询案例,展示了如何利用Python实现从数据请求到网页解析的完整流程。掌握这种技能,不仅可以在专利查询中应用,也可以在其他数据采集场景中举一反三。希望这篇文章能为你在数据采集领域提供有价值的参考。未来,随着技术的发展,我们将看到更加智能、高效的采集方式,而Python无疑是其中的重要工具。 *本文为技术探讨,实际应用中请遵守相关法律法规和网站使用协议。*