项目
博客
归档
资源链接
关于我
项目
博客
归档
资源链接
关于我
性能优化高频面试题集锦
2020-11-12
·
softbabet博主
·
原创
·
性能调优
·
本文共 3,830个字,预计阅读需要 13分钟。
## tomcat部分 ### 一、tomcat有哪些配置项可以优化? 1、server.xml文件中禁用ajp协议(新版中默认是屏蔽的),减少不必要的线程开销 ```xml <!--<Connector port="8009" protocol="AJP/1.3" redirectPort="8443" />--> ``` 2、server.xml文件修改元素,使用线程池提高性能 ```xml <!‐‐将注释打开(注释没打开的情况下默认10个线程,最小10,最大200)‐‐> <Executor name="tomcatThreadPool" namePrefix="catalina‐exec‐" maxThreads="500" minSpareThreads="50" prestartminSpareThreads="true" maxQueueSize="100"/> <!‐‐ 参数说明: maxThreads:最大并发数,默认设置 200,一般建议在 500 ~ 1000,根据硬件设施和业 务来判断 minSpareThreads:Tomcat 初始化时创建的线程数,默认设置 25 prestartminSpareThreads: 在 Tomcat 初始化的时候就初始化 minSpareThreads 的 参数值,如果不等于 true,minSpareThreads 的值就没啥效果了 maxQueueSize,最大的等待队列数,超过则拒绝请求 ‐‐> <!‐‐在Connector中设置executor属性指向上面的执行器‐‐> <Connector executor="tomcatThreadPool" port="8080" protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="8443" /> ``` 3、server.xml文件中修改连接器,可以使用NIO2通道提高性能 设置nio2: ```xml <Connector executor="tomcatThreadPool" port="8080" protocol="org.apache.coyote.http11.Http11Nio2Protocol" connectionTimeout="20000" redirectPort="8443" /> ``` ### 二、tomcat堆栈中有哪些常见线程?分别有什么用途? **1、main线程** main线程是tomcat的主要线程,其主要作用是通过启动包来对容器进行点火: main线程一路启动了Catalina,StandardServer[8005],StandardService[Catalina],StandardEngine[Catalina] engine内部组件都是异步启动,engine这层才开始继承ContainerBase,engine会调用父类的startInternal()方法,里面由startStopExecutor线程提交FutureTask任务,异步启动子组件StandardHost, StandardEngine[Catalina].StandardHost[localhost] main->Catalina->StandardServer->StandardService->StandardEngine->**StandardHost**,黑体开始都是异步启动。 ->启动Connector main的作用就是把容器组件拉起来,然后阻塞在8005端口,等待关闭。 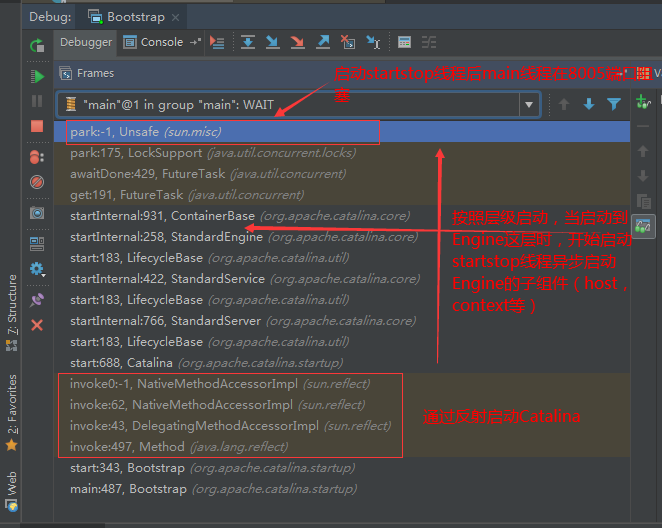 **2、localhost-startStop线程** Tomcat容器被点火起来后,并不是傻傻的按照次序一步一步的启动,而是在engine组件中开始用该线程提交任务,按照层级进行异步启动,对于每一层级的组件都是采用startStop线程进行启动,我们观察一下idea中的线程堆栈就可以发现:启动异步,部署也是异步 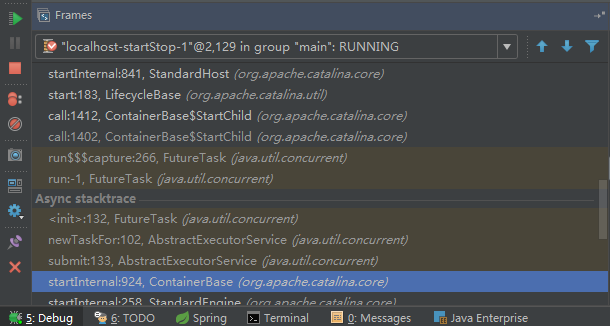 这个startstop线程实际代码调用就是采用的JDK自带线程池来做的,启动位置就是ContainerBase的组件父类的startInternal(): 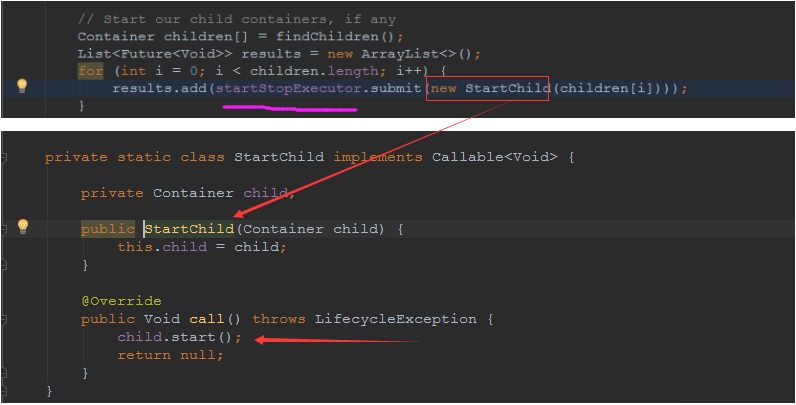 因为从Engine开始往下的容器组件都是继承这个ContainerBase,所以相当于每一个组件启动的时候,除了对自身的状态进行设置,都会启动startChild线程启动自己的孩子组件。 而这个线程仅仅就是在启动时,当组件启动完成后,那么该线程就退出了,生命周期仅仅限于此。 **3、AsyncFileHandlerWriter线程** 日志输出线程: 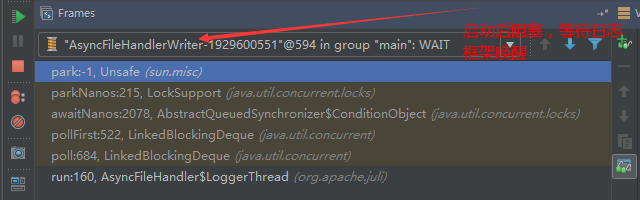 顾名思义,该线程是用于异步文件处理的,它的作用是在Tomcat级别构架出一个输出框架,然后不同的日志系统都可以对接这个框架,因为日志对于服务器来说,是非常重要的功能。 如下,就是juli的配置:  该线程主要的作用是通过一个LinkedBlockingDeque来与log系统对接,该线程启动的时候就有了,全生命周期。 **4、ContainerBackgroundProcessor线程** Tomcat在启动之后,不能说是死水一潭,很多时候可能会对Tomcat后端的容器组件做一些变化,例如部署一个应用,相当于你就需要在对应的Standardhost加上一个StandardContext,也有可能在热部署开关开启的时候,对资源进行增删等操作,这样应用可能会重新reload。 也有可能在生产模式下,对class进行重新替换等等,这个时候就需要在Tomcat级别中有一个线程能实时扫描Tomcat容器的变化,这个就是ContainerbackgroundProcessor线程了: (本地源码StandardContext类的5212行启动) 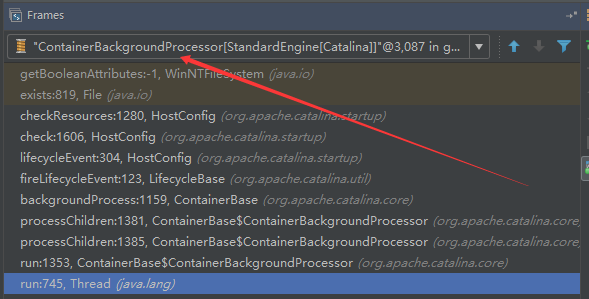 我们可以看到这个代码,也就是在ContainerBase中: 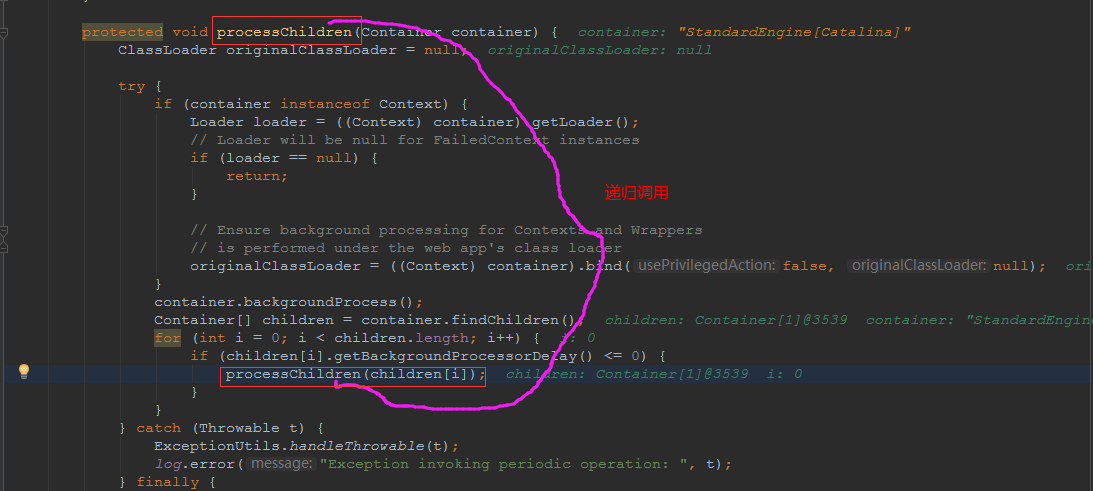 这个线程是一个递归调用,也就是说,每一个容器组件其实都有一个backgroundProcessor,而整个Tomcat就点起一个线程开启扫描,扫完儿子,再扫孙子(实际上来说,主要还是用于StandardContext这一级,可以看到StandardContext这一级: 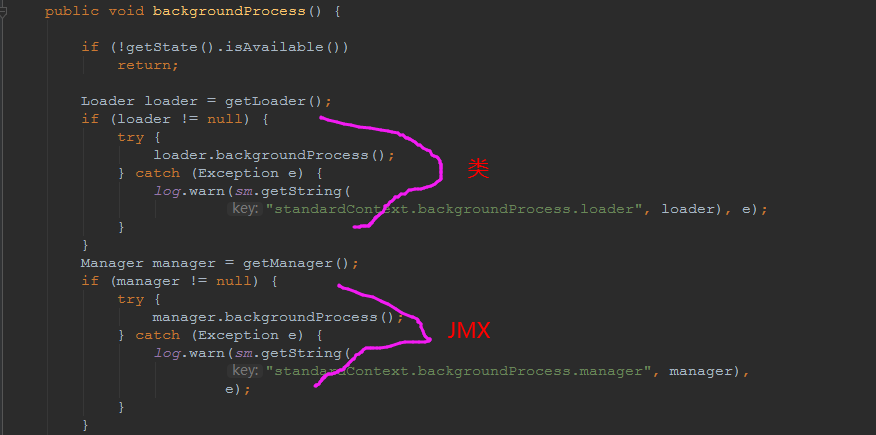 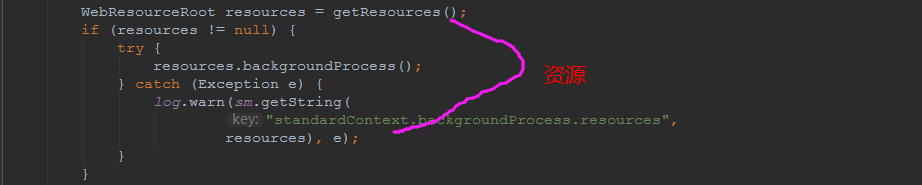 我们可以看到,每一次backgroundProcessor,都会对该应用进行一次全方位的扫描,这个时候,当你开启了热部署的开关,一旦class和资源发生变化,立刻就会reload。 tomcat9中已经被Catalina-Utility线程替代。 **5、acceptor线程** Connector(实际是在**AbstractProtocol**类中)初始化和启动之时,启动了Endpoint,Endpoint就会启动**poller**线程和**Acceptor**线程。Acceptor底层就是ServerSocket.accept()。返回Socket之后丢给NioChannel处理,之后通道和poller线程绑定。 ***acceptor->poller->exec\*** 无论是NIO还是BIO通道,都会有Acceptor线程,该线程就是进行socket接收的,它不会继续处理,如果是NIO的,无论是新接收的包还是继续发送的包,直接就会交给Poller,而BIO模式,Acceptor线程直接把活就给工作线程了: 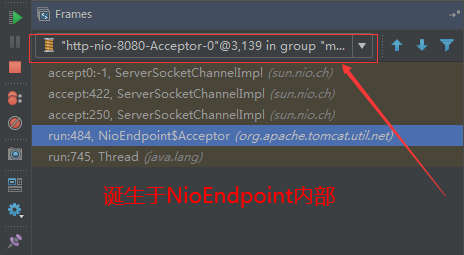 如果不配置,Acceptor线程默认开始就开启1个,后期再随着压力增大而增长: 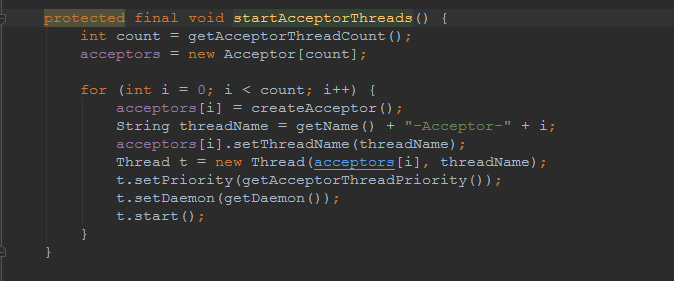 上述启动代码在AbstractNioEndpoint的startAcceptorThreads方法中。 **6、ClientPoller线程** NIO和APR模式下的Tomcat前端,都会有Poller线程: 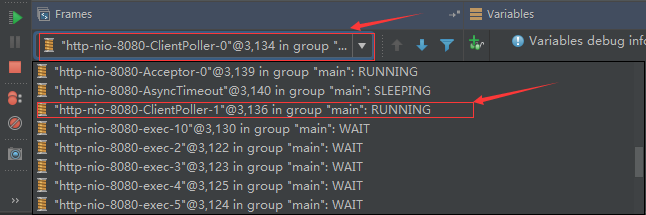 对于Poller线程实际就是继续接着Acceptor进行处理,展开Selector,然后遍历key,将后续的任务转交给工作线程(exec线程),起到的是一个缓冲,转接,和NIO事件遍历的作用,具体代码体现如下(NioEndpoint类): 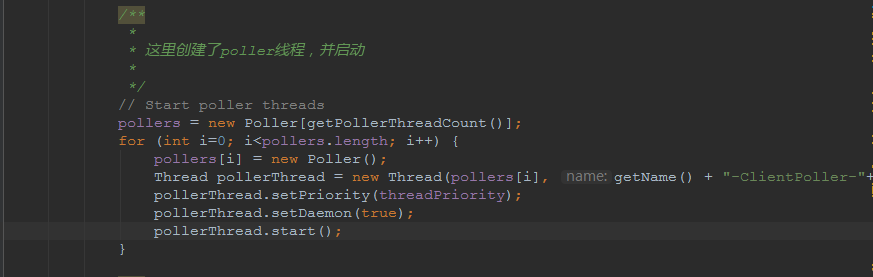 上述的代码在NioEndpoint的startInternal中,默认开始开启2个Poller线程,后期再随着压力增大增长,可以在Connector中进行配置。 **7、exe线程(默认10个)** 也就是SocketProcessor线程,我们可以看到,上述几个线程都是定义在NioEndpoint内部线程类。NIO模式下,Poller线程将解析好的socket交给SocketProcessor处理,它主要是http协议分析,攒出Response和Request,然后调用Tomcat后端的容器: 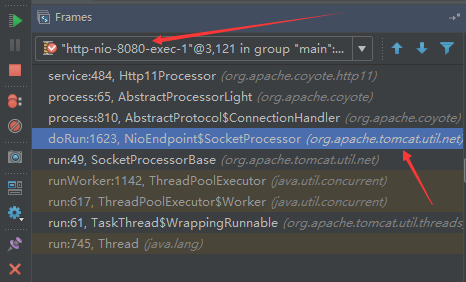 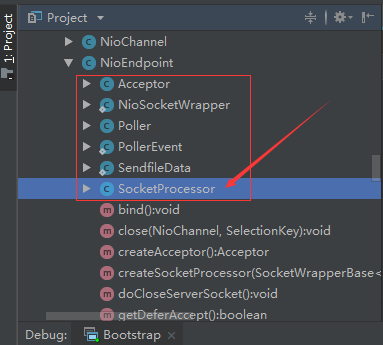 该线程的重要性不言而喻,Tomcat主要的时间都耗在这个线程上,所以我们可以看到Tomcat里面有很多的优化,配置,都是基于这个线程的,尽可能让这个线程减少阻塞,减少线程切换,甚至少创建,多利用。 下面就是NIO模式下创建的工作线程: 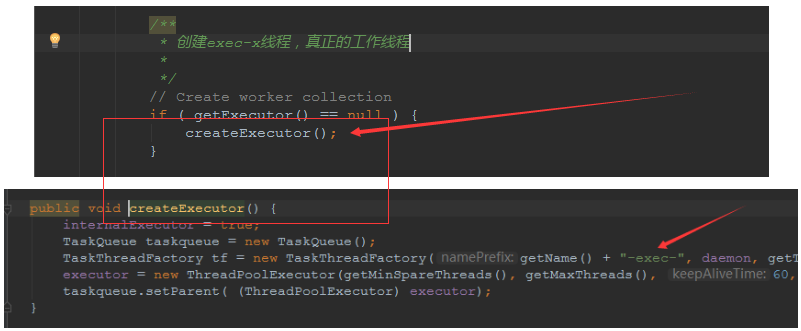 实际上也是JDK的线程池,只不过基于Tomcat的不同环境参数,对JDK线程池进行了定制化而已,本质上还是JDK的线程池。 **8、NioBlockingSelector.BlockPoller(默认2个)** Nio方式的Servlet阻塞输入输出检测线程。实际就是在Endpoint初始化的时候启动selectorPool,selectorPool再启动selector,selector内部启动BlokerPoller线程。 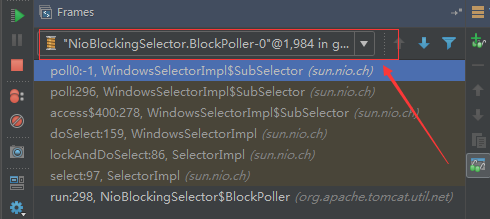 该线程在前面的NioBlockingPool中讲得很清楚了,其NIO通道的Servlet输入和输出最终都是通过NioBlockingPool来完成的,而NioBlockingPool又根据Tomcat的场景可以分成阻塞或者是非阻塞的,对于阻塞来讲,为了等待网络发出,需要启动一个线程实时监测网络socketChannel是否可以发出包,而如果不这么做的话,就需要使用一个while空转,这样会让工作线程一直损耗。 只要是阻塞模式,并且在Tomcat启动的时候,添加了—D参数 org.apache.tomcat.util.net.NioSelectorShared 的话,那么就会启动这个线程。 大体上启动顺序如下: ```java //bind方法在初始化就完成了 Endpoint.bind(){ //selector池子启动 selectorPool.open(){ //池子里面selector再启动 blockingSelector.open(getSharedSelector()){ //重点这句 poller = new BlockPoller(); poller.selector = sharedSelector; poller.setDaemon(true); poller.setName("NioBlockingSelector.BlockPoller-"+ (threadCounter.getAndIncrement())); //这里启动 poller.start(); } } } ``` **9、AsyncTimeout线程** 该线程为tomcat7及之后的版本才出现的,注释其实很清楚,该线程就是检测异步request请求时,触发超时,并将该请求再转发到工作线程池处理(也就是Endpoint处理)。 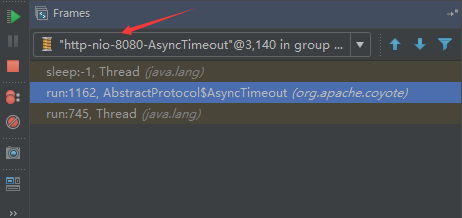 AsyncTimeout线程也是定义在**AbstractProtocol**内部的,在start()中启动。AbstractProtocol是个极其重要的类,**他持有\*Endpoint\*和\*ConnectionHandler\***这两个tomcat前端非常重要的类 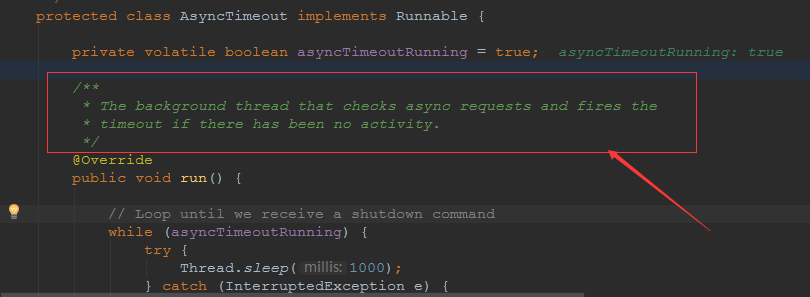 **10、其他线程(例如ajp相关线程)** ajp工作线程处理的是ajp协议的相关请求,这个请求主要是用于http apache服务器和tomcat之间的数据交换,该数据交换用的就是ajp协议,和exec工作线程差不多,默认也是启动10个,端口号是8009。优化时如果没有用到http apache的话就可以把这个协议关掉。 Tomcat本身还有很多其它的线程,远远不止这些,例如如果开启了sendfile,那么对sendfile就是开启一个线程来进行操作,这种功能的线程开启还有很多。 Tomcat作为一款优秀的服务器,不可能就只有1个线程,而是多个线程之间相互配合完成功能,而且很多功能尽量异步处理,尽可能的减少线程切换。所以线程并不是越多越好,因此线程的控制也尤为关键。 ### 三、Tomcat 的 bio 模式改为 nio 模式,是否能提高服务器的吞吐量?为什么在配置一样的情况下,两种模式压出来的吞吐量差不多? 这种情况主要就是要看是不是整个系统都异步化了,因为tomcat的nio只是将网络io异步化了,就是接收和读写异步化了,但是网络报文接受完后还是要交给业务线程池,如果你的业务是阻塞的或者较耗时的话是没办法提升整个系统的吞吐量的,除非将整个项目都异步化,现在压测cpu如果还没有打满的话就可以继续优化,但如果bio都能打满cpu就说明已经到物理极限了,只能在代码层去优化了。 ### 四、对比nio,bio一开始能接收的量比nio大,什么原因? bio接收请求是线程池里面的线程接收的,也就是说你的线程池如果设为600,就有600个线程能接收,自然就会满打满算,但是nio是只有cpu数个线程负责接收的(默认10个)。 ### 五、nio的优势是什么?是不是 nio 模式下 tomcat 默认能保持10000条连接,而bio模式则达不到? 简单地说,nio模式最大化压榨了CPU,把时间片更好利用起来。通俗地说,bio hold住连接不干活也占用线程,nio hold住连接不干活也没关系,让需要处理的连接先执行就行了。 ### 六、nio模式是不是更适合做tcp长连接,用少量线程hold住大量的连接,节省资源?但tomcat现在都是短连接,nio抗并发并没有比bio强吗? nio适合大量长连接,而且大部分是只hold住但不处理的场景,如果你能将项目异步化的话nio肯定比bio扛得连接多。bio模式其实压测时是打不满CPU的,所以采用nio来压榨CPU,如果bio都能打满CPU,那就没必要设计nio 和异步化了,因为已经达到物理极限了,没有办法继续压榨了,只能去优化代码。 ### 七、bio模式下将最大线程数不断调大,直到打满CPU,这种情况和nio异步比较,更倾向于哪一种? bio模式达到峰值后会导致接收不了连接,操作系统层的连接队列满了则会拒绝连接。另外一个是,系统不可能开很多线程,bio开太多线程可能会直接卡死,线程切换花销很大,主要是要将阻塞的环节异步出来,这样线程就能高效干活了。nio模式还是比bio高效很多,因为bio模式光网络读写就可能阻塞很长时间了,而nio负责网络io的异步化,而其他步骤的异步化要自己另外考虑。 ### 八、Tomcat中的NIO2通道是如何保证高性能的? nio2通道是基于java AIO,采用的是proactor模式,是纯异步模式,这比NIO基于reacactor模式效率要高。所有的操作都是由操作系统回调异步完成。 ### 九、研究过tomcat的NioEndpoint源码吗?请阐述下Reactor多线程模型在tomcat中的实现。 **tomcat的底层网络NIO通信基于主从Reactor多线程模型**。 它有三大线程组分别用于处理不同的逻辑: **Acceptor线程**:等待和接收客户端连接。在接收到连接后,创建SocketChannel并将其注册到poller线程。 **poller线程**:将SocketChannel放到selector上注册读事件,轮询selector,获取就绪的SelectionKey,并将就绪的SelectionKey(或SocketChannel)委托给工作线程。 **工作线程**:执行真正的业务逻辑。 *备注:Acceptor线程和poller线程之间有一个SocketChannel队列,Acceptor线程负责将SocketChannel推送到队列,poller线程负责从队列取出SocketChannel。poller线程从队列取出SocketChannel后,紧接着会把它放到selector上注册读事件。* **主从Reactor多线程模型** 主从Reactor线程模型的特点是:服务端用于接收客户端连接的不再是1个单独的NIO线程,而是一个独立的NIO线程池。Acceptor接收到客户端TCP连接请求处理完成后(可能包含接入认证等),将新创建的SocketChannel注册到IO线程池(sub reactor线程池)的某个IO线程上,由它负责SocketChannel的读写和编解码工作。Acceptor线程池仅仅只用于客户端的登陆、握手和安全认证,一旦链路建立成功,就将链路注册到后端subReactor线程池的IO线程上,由IO线程负责后续的IO操作。 它的线程模型如下图所示: 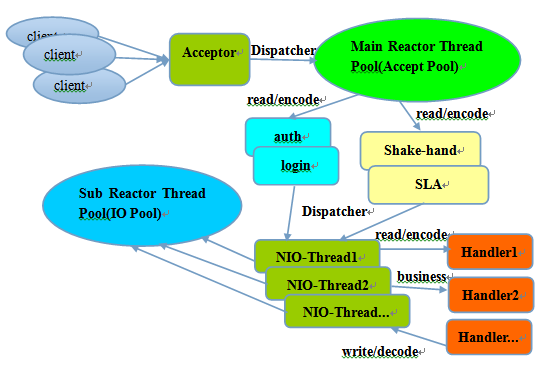 **工作流程总结如下** 从主线程池中随机选择一个Reactor线程作为Acceptor线程,用于绑定监听端口,接收客户端连接; Acceptor线程接收客户端连接请求之后创建新的SocketChannel,将其注册到主线程池的其它Reactor线程上,由其负责接入认证、IP黑白名单过滤、握手等操作; 步骤2完成之后,业务层的链路正式建立,将SocketChannel从主线程池的Reactor线程的多路复用器上摘除,重新注册到Sub线程池的线程上,用于处理I/O的读写操作。 ## mysql部分 ### 一、SQL语句优化的总体原则有哪些? 1. 优化更需要优化的SQL 2. 定位优化对象的性能瓶颈 3. 明确的优化目标 4. 从Explain执行计划入手 5. 多使用profile 6. 永远用小结果集驱动大结果集 7. 尽可能在索引中完成排序 8. 只取出自己需要的列 9. 仅仅使用最有效的过滤条件 10. 尽可能避免复杂的Join和子查询 ### 二、如何理解MySQL中加锁原理? mysql加锁机制 : 根据类型可分为共享锁(SHARED LOCK)和排他锁(EXCLUSIVE LOCK)或者叫读锁(READ LOCK)和写锁(WRITE LOCK)。 根据粒度划分又分表锁和行锁。表锁由数据库服务器实现,行锁由存储引擎实现。 ### 三、MySQL死锁形成的原因是什么? 争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去. 此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。 表级锁不会产生死锁.所以解决死锁主要还是针对于最常用的InnoDB。 死锁的关键在于:两个(或以上)的Session加锁的顺序不一致。 那么对应的解决死锁问题的关键就是:让不同的session加锁有次序。 ### 四、请阐述建立索引的原则有哪些? 1、定义主键的数据列一定要建立索引。 2、定义有外键的数据列一定要建立索引。 3、对于经常查询的数据列最好建立索引。 4、对于需要在指定范围内的快速或频繁查询的数据列。 5、经常用在WHERE子句中的数据列。 6、经常出现在关键字order by、group by、distinct后面的字段,建立索引。如果建立的是复合索引,索引的字段顺序要和这些关键字后面的字段顺序一致,否则索引不会被使用。 7、对于那些查询中很少涉及的列,重复值比较多的列不要建立索引。 8、对于定义为text、image和bit的数据类型的列不要建立索引。 9、对于经常存取的列避免建立索引。 10、限制表上的索引数目。对一个存在大量更新操作的表,所建索引的数目一般不要超过3个,最多不要超过5个。索引虽说提高了访问速度,但太多索引会影响数据的更新操作。 11、对复合索引,按照字段在查询条件中出现的频度建立索引。在复合索引中,记录首先按照第一个字段排序。对于在第一个字段上取值相同的记录,系统再按照第二个字段的取值排序,以此类推。因此只有复合索引的第一个字段出现在查询条件中,该索引才可能被使用,因此将应用频度高的字段,放置在复合索引的前面,会使系统最大可能地使用此索引,发挥索引的作用。 ### 五、mysql性能调优主要是针对执行计划中的哪些属性进行优化? **主要关注type列,key列,extra列** type列依次性能从好到差:system,const,eq_ref,ref,fulltext,ref_or_null,unique_subquery,index_subquery,range,index_merge,index,ALL,除了all之外,其他的type都可以使用到索引,除了index_merge之外,其他的type只可以用到一个索引。一般来说,好的sql查询至少达到range级别,最好能达到ref。 key列正常情况要是非NULL,如果是NULL,表示没有用索引,性能低下。 extra列主要关注是不是用了临时表排序,索引等等。例如:using temporary,using filesort等都是需要优化的。 ### 六、mysql中多表join的优化思路有哪些? **1、尽可能减少Join语句中的Nested Loop的循环总次数** 如何减少Nested Loop的循环总次数? 最有效的办法只有一个,那就是让驱动表的结果集尽可能的小,永远用小结果集驱动大的结果集。为什么?因为驱动结果集越大,意味着需要循环的次数越多,也就是说在被驱动结果集上面所需要执行的查询检索次数会越多。比如,当两个表(表 A 和 表 B)Join的时候,如果表A通过WHERE条件过滤后有10条记录,而表B有20条记录。如果我们选择表A作为驱动表,也就是被驱动表的结果集为20,那么我们通过Join条件对被驱动表(表B)的比较过滤就会有10次。反之,如果我们选择表B作为驱动表,则需要有20次对表A的比较过滤。当然,此优化的前提条件是通过Join条件对各个表的每次访问的资源消耗差别不是太大。如果访问存在较大的差别的时候(一般都是因为索引的区别),我们就不能简单的通过结果集的大小来判断需要Join语句的驱动顺序,而是要通过比较循环次数和每次循环所需要的消耗的乘积的大小来得到如何驱动更优化。 **2、优先优化Nested Loop的内层循环** 这不仅仅是在数据库的Join中应该做的,实际上在我们优化程序语言的时候也有类似的优化原则。内层循环是循环中执行次数最多的,每次循环节约很小的资源,在整个循环中就能节约很大的资源。 **3、保证Join语句中被驱动表上Join条件字段已经被索引** 保证被驱动表上Join条件字段已经被索引的目的,正是针对上面两点的考虑,只有让被驱动表的Join条件字段被索引了,才能保证循环中每次查询都能够消耗较少的资源,这也正是优化内层循环的实际优化方法。 **4、当无法保证被驱动表的Join条件字段被索引且内存资源充足的前提下,不要太吝惜Join** **Buffer的设置** 当在某些特殊的环境中,我们的Join必须是All,Index,range或者是index_merge类型的时候, Join Buffer就会派上用场了。在这种情况下,Join Buffer的大小将对整个Join语句的消耗起到非常关键的作用。 ### 七、请阐述order by语句的优化方案 **利用索引实现数据排序的方法是MySQL中实现结果集排序的最佳做法。** 因为这样可以完全避免因为排序计算所带来的资源消耗。所以,在我们优化sql语句中的ORDER BY的时候,尽可能利用已有的索引来避免实际的排序计算,可以很大幅度的提升ORDER BY操作的性能。在有些sql的优化过程中,即使为了避免实际的排序操作而调整索引字段的顺序,甚至是增加索引字段也是值得的。当然,在调整索 引之前,同时还需要评估调整该索引对其他sql所带来的影响,平衡整体得失。 ### 八、group by语句实现的内部机制是什么?如何优化? MySQL中,GROUP BY的实现有多种(三种)方式,其中有两种方式会利用现有的索引信息来完成GROUP BY,另外一种为完全无法使用索引的场景下使用。 **1、用松散(Loose)索引扫描实现GROUP BY** 当MySQL完全利用索引扫描来实现GROUP BY的时候,并不需要扫描所有满足条件的索引键即可完成操作得出结果 ***什么松散索引扫描的效率会很高?\*** 因为在没有WHERE子句,也就是必须经过全索引扫描的时候,松散索引扫描需要读取的键值数量与分组的组数量一样多,也就是说比实际存在的键值数目要少很多。而在WHERE子句包含范围判断式或者等值表达式的时候,松散索引扫描查找满足范围条件的每个组的第1个关键字,并且再次读取尽可能最少数量的关键字。 **2、用紧凑(Tight)索引扫描实现GROUP BY** 紧凑索引扫描实现GROUP BY和松散索引扫描的区别主要在于他需要在扫描索引的时候,读取所有满足条件的索引键,然后再根据读取的数据来完成GROUP BY操作得到相应结果。 **3、用临时表实现 GROUP BY** 前面两种GROUP BY的实现方式都是在有可以利用的索引的时候使用的,当MySQL Query Optimizer无法找到合适的索引可以利用的时候,就不得不先读取需要的数据,然后通过临时表来完成GROUP BY操作。 ### 九、索引的弊端有哪些? **针对增、删、改比较频繁的操作列上,索引会带来额外的开销(索引裂变重排等操作)。** 假设我们在Table ta中的Column ca列创建了索引idx_ta_ca,那么任何更新Column ca的操作,MySQL都需要在更新表中Column ca的同时,也更新Column ca的索引数据,调整因为更新所带来键值变化后的索引信息。而如果我们没有对Column ca进行索引的话,MySQL所需要做的仅仅只是更新表中Column ca的信息。这样,所带来的最明显的资源消耗就是增加了更新所带来的IO量和调整索引所致的计算量。此外,Column ca的索引idx_ta_ca是需要占用存储空间的,而且随着Table ta数据量的增长,idx_ta_ca所占用的空间也会不断增长。所以索引还会带来存储空间资源消耗的增长。 ## netty部分 ### 一、请阐述Netty的执行流程。 1、创建ServerBootStrap实例 2、设置并绑定Reactor线程池:EventLoopGroup,EventLoop就是处理所有注册到本线程的Selector上面的Channel 3、设置并绑定服务端的channel 4、创建处理网络事件的ChannelPipeline和handler,网络时间以流的形式在其中流转,handler完成多数的功能定制:比如编解码 SSl安全认证 5、绑定并启动监听端口 6、当轮询到准备就绪的channel后,由Reactor线程:NioEventLoop执行pipline中的方法,最终调度并执行channelHandler ### 二、Netty高性能体现在哪些方面? 1、传输:IO模型在很大程度上决定了框架的性能,相比于bio,netty建议采用异步通信模式,因为nio一个线程可以并发处理N个客户端连接和读写操作,这从根本上解决了传统同步阻塞IO一连接一线程模型,架构的性能、弹性伸缩能力和可靠性都得到了极大的提升。正如源码中所示,使用的是NioEventLoopGroup和NioSocketChannel来提升传输效率。 2、协议:采用什么样的通信协议,对系统的性能极其重要,netty默认提供了对Google Protobuf的支持,也可以通过扩展Netty的编解码接口,用户可以实现其它的高性能序列化框架。 3、线程:netty使用了Reactor线程模型,但Reactor细分模型的不同,对性能的影响也非常大,下面介绍常用的Reactor线程模型有三种,分别如下: - Reactor单线程模型:单线程模型的线程即作为NIO服务端接收客户端的TCP连接,又作为NIO客户端向服务端发起TCP连接,即读取通信对端的请求或者应答消息,又向通信对端发送消息请求或者应答消息。理论上一个线程可以独立处理所有IO相关的操作,但一个NIO线程同时处理成百上千的链路,性能上无法支撑,即便NIO线程的CPU负荷达到100%,也无法满足海量消息的编码、解码、读取和发送,又因为当NIO线程负载过重之后,处理速度将变慢,这会导致大量客户端连接超时,超时之后往往会进行重发,这更加重了NIO线程的负载,最终会导致大量消息积压和处理超时,NIO线程会成为系统的性能瓶颈。 - Reactor多线程模型:有专门一个NIO线程用于监听服务端,接收客户端的TCP连接请求;网络IO操作(读写)由一个NIO线程池负责,线程池可以采用标准的JDK线程池实现。但百万客户端并发连接时,一个nio线程用来监听和接受明显不够,因此有了主从多线程模型。 - 主从Reactor多线程模型:利用主从NIO线程模型,可以解决1个服务端监听线程无法有效处理所有客户端连接的性能不足问题,即把监听服务端,接收客户端的TCP连接请求分给一个线程池。因此,在代码中可以看到,我们在server端选择的就是这种方式,并且也推荐使用该线程模型。在启动类中创建不同的EventLoopGroup实例并通过适当的参数配置,就可以支持上述三种Reactor线程模型。 ### 三、Netty的零拷贝体现在哪里,与操作系统上的有什么区别? Zero-copy就是在操作数据时, 不需要将数据buffer从一个内存区域拷贝到另一个内存区域。 少了一次内存的拷贝,CPU的效率就得到的提升。在OS层面上的Zero-copy 通常指避免在 用户态(User-space)与内核态(Kernel-space)之间来回拷贝数据。Netty的Zero-copy完全是在用户态(Java 层面)的, 更多的偏向于优化数据操作。 - Netty的接收和发送ByteBuffer采用DIRECT BUFFERS,使用堆外直接内存进行Socket读写,不需要进行字节缓冲区的二次拷贝。如果使用传统的堆内存(HEAP BUFFERS)进行Socket读写,JVM会将堆内存Buffer拷贝一份到直接内存中,然后才写入Socket中。相比于堆外直接内存,消息在发送过程中多了一次缓冲区的内存拷贝。 - Netty提供了组合Buffer对象,可以聚合多个ByteBuffer对象,用户可以像操作一个Buffer那样方便的对组合Buffer进行操作,避免了传统通过内存拷贝的方式将几个小Buffer合并成一个大的Buffer。 - Netty的文件传输采用了transferTo方法,它可以直接将文件缓冲区的数据发送到目标Channel,避免了传统通过循环write方式导致的内存拷贝问题。 ### 四、原生的NIO存在Epoll bug、Netty是怎么解决的? Java NIO Epoll会导致Selector空轮询,最终导致CPU100% 。 Netty对Selector的select 操作周期进行统计,每完成一次空的select操作进行一次计数,若在某个周期内连续发生 N次空轮询,则判断触发了Epoll死循环Bug 。 ### 五、Netty自己实现的ByteBuf有什么优点? 1、它可以被用户自定义的缓冲区类型扩展 2、通过内置的符合缓冲区类型实现了透明的零拷贝 3、读和写使用了不同的索引 4、支持方法的链式调用 5、支持池化 ### 六、Netty为什么要实现内存管理? 1、频繁分配、释放buffer时减少了GC压力。 2、在初始化新buffer时减少内存带宽消耗( 初始化时不可避免的要给buffer数组赋初始值 )。 3、及时的释放direct buffer。 ### 七、TCP粘包/拆包的产生原因,应该这么解决? **TCP 是以流的方式来处理数据,所以会导致粘包/拆包** 拆包:一个完整的包可能会被TCP拆分成多个包进行发送。 粘包:也可能把小的封装成一个大的数据包发送。 **Netty中提供了多个Decoder解析类用于解决上述问题** FixedLengthFrameDecoder 、LengthFieldBasedFrameDecoder ,固定长度是消息头指定消息长度的一种形式,进行粘包拆包处理的。 LineBasedFrameDecoder 、DelimiterBasedFrameDecoder ,换行是于指定消息边界方式的一种形式,进行消息粘包拆包处理的。 ### 八、netty业务handler中channelread方法造成内存泄漏的原因是什么? 如果业务handler继承的是ChannelInboundHandlerAdapter,那么在调用完channelRead方法之后,netty不会主动释放内存,必须进行手工释放。 ### 九、netty并行执行优化策略有哪些?分别用在什么场景中? **1、使用netty提供的EventExecutorGroup线程组** 如果客户端的并发连接数channel多,且每个客户端channel的业务请求阻塞不多,那么使用EventExecutorGroup **2、使用jdk提供的线程组ExecutorService** 如果客户端并发连接数channel不多,但是客户端channel的业务请求阻塞较多(复杂业务处理和数据库处理),那么使用ExecutorService ## JVM部分 ### 一、Java会存在内存泄漏吗?请简单描述 内存泄漏是指不再被使用的对象或者变量一直被占据在内存中。理论上来说,Java是有GC垃圾回收机制的,也就是说,不再被使用的对象,会被GC自动回收掉,自动从内存中清除。 但是,即使这样,Java也还是存在着内存泄漏的情况,java导致内存泄露的原因很明确:长生命周期的对象持有短生命周期对象的引用就很可能发生内存泄露,尽管短生命周期对象已经不再需要,但是因为长生命周期对象持有它的引用而导致不能被回收,这就是java中内存泄露的发生场景。 ### 二、请解释内存中的栈(stack)、堆(heap)和方法区(method area)的用法 通常我们定义一个基本数据类型的变量,一个对象的引用,还有就是函数调用的现场保存都使用JVM中的栈空间; 而通过new关键字和构造器创建的对象则放在堆空间,堆是垃圾收集器管理的主要区域,由于现在的垃圾收集器都采用分代收集算法,所以堆空间还可以细分为新生代和老生代,再具体一点可以分为Eden、Survivor(又可分为From Survivor和To Survivor)、Tenured; 方法区和堆都是各个线程共享的内存区域,用于存储已经被JVM加载的类信息、常量、静态变量、JIT编译器编译后的代码等数据; 程序中的字面量(literal)如直接书写的100、”hello”和常量都是放在常量池中,常量池是方法区的一部分。 栈空间操作起来最快但是栈很小,通常大量的对象都是放在堆空间,栈和堆的大小都可以通过JVM的启动参数来进行调整,栈空间用光了会引发StackOverflowError,而堆和常量池空间不足则会引发OutOfMemoryError。 ```java String str = new String("hello"); ``` 上面的语句中变量str放在栈上,用new创建出来的字符串对象放在堆上,而”hello”这个字面量是放在方法区的。 补充1:较新版本的Java(从Java 6的某个更新开始)中,由于JIT编译器的发展和”逃逸分析”技术的逐渐成熟,栈上分配、标量替换等优化技术使得对象一定分配在堆上这件事情已经变得不那么绝对了。 补充2:运行时常量池相当于Class文件常量池具有动态性,Java语言并不要求常量一定只有编译期间才能产生,运行期间也可以将新的常量放入池中,String类的intern()方法就是这样的。 看看下面代码的执行结果是什么并且比较一下Java 7以前和以后的运行结果是否一致。 ```java String s1 = new StringBuilder("go").append("od").toString(); System.out.println(s1.intern() == s1); String s2 = new StringBuilder("ja").append("va").toString(); System.out.println(s2.intern() == s2); ``` ### 三、请解释StackOverflowError和OutOfMemeryError的区别? StackOverflowError栈溢出,一般由于递归过多,调用方法过多导致。 OutOfMemeryError堆内存溢出,即OOM,由于堆内存中没有被GC回收的对象过多导致。 出现OOM的原因: 1、Java虚拟机的堆内存设置不够,可以通过参数-Xms和-Xmx来调优 2、程序中创建了大量对象,并且长时间不能被被垃圾回收器回收(存在引用) ### 四、JVM的引用类型有哪些? 强引用:当内存不足的时候,JVM宁可出现OutOfMemoryError错误停止,也需要进行保存,并且不会将此空间回收。在引用期间和栈有联系就无法被回收 软引用:当内存不足的时候,进行对象的回收处理,往往用于高速缓存中;mybatis就是 弱引用:不管内存是否紧张,只要有垃圾了就立即回收 幽灵引用:和没有引用是一样的 ### 五、JVM的常用的涉及内存调优的参数有哪些? 两个 -Xms:堆内存初始化大小,一般默认为物理内存的六十四分之一 -Xmx:堆内存最大分配空间,一般默认为物理内存的四分之一 在内存泄漏问题排查时,采取主动内存调试法,往下调整内存大小,尽快让问题复现 ### 六、什么是类的加载? 类的加载指的是将类的.class文件中的二进制数据读入到内存中,将其放在运行时数据区的方法区内,然后在堆区创建一个java.lang.Class对象,用来封装类在方法区内的数据结构。类的加载的最终产品是位于堆区中的Class对象,Class对象封装了类在方法区内的数据结构,并且向Java程序员提供了访问方法区内的数据结构的接口。 ### 七、描述一下JVM加载class文件的原理机制? JVM中类的装载是由类加载器(ClassLoader)和它的子类来实现的,Java中的类加载器是一个重要的Java运行时系统组件,它负责在运行时查找和装入类文件中的类。 由于Java的跨平台性,经过编译的Java源程序并不是一个可执行程序,而是一个或多个类文件。当Java程序需要使用某个类时,JVM会确保这个类已经被加载、连接(验证、准备和解析)和初始化。类的加载是指把类的.class文件中的数据读入到内存中,通常是创建一个字节数组读入.class文件,然后产生与所加载类对应的Class对象。加载完成后,Class对象还不完整,所以此时的类还不可用。当类被加载后就进入连接阶段,这一阶段包括验证、准备(为静态变量分配内存并设置默认的初始值)和解析(将符号引用替换为直接引用)三个步骤。 最后JVM对类进行初始化,包括: - 如果类存在直接的父类并且这个类还没有被初始化,那么就先初始化父类。 - 如果类中存在初始化语句,就依次执行这些初始化语句。 类的加载是由类加载器完成的,类加载器包括:根加载器(BootStrap)、扩展加载器(Extension)、系统加载器(System)和用户自定义类加载器(java.lang.ClassLoader的子类)。 从Java 2(JDK 1.2)开始,类加载过程采取了父亲委托机制(PDM)。PDM更好的保证了Java平台的安全性,在该机制中,JVM自带的Bootstrap是根加载器,其他的加载器都有且仅有一个父类加载器。类的加载首先请求父类加载器加载,父类加载器无能为力时才由其子类加载器自行加载。JVM不会向Java程序提供对Bootstrap的引用。下面是关于几个类加载器的说明: - Bootstrap:一般用本地代码实现,负责加载JVM基础核心类库(rt.jar)。 - Extension:从java.ext.dirs系统属性所指定的目录中加载类库,它的父加载器是Bootstrap。 - System:又叫应用类加载器,其父类是Extension。它是应用最广泛的类加载器。它从环境变量classpath或者系统属性java.class.path所指定的目录中记载类,是用户自定义加载器的默认父加载器。 ### 八、jvm是如何实现多线程的? 线程是比进程更轻量级的调度执行单位。线程可以把一个进程的资源分配和执行调度分开。一个进程里可以启动多条线程,各个线程可共享该进程的资源(内存地址,文件IO等),又可以独立调度。线程是CPU调度的基本单位。 主流OS都提供线程实现。Java语言提供对线程操作的同一API,每个已经执行start(),且还未结束的java.lang.Thread类的实例,代表了一个线程。 Thread类的关键方法,都声明为Native。这意味着这个方法无法或没有使用平台无关的手段来实现,也可能是为了执行效率。 程序计数器是一个线程隔离的数据区,说白了就是每一个线程都会单独开辟一块内存区域给程序计数器,并且线程之间这块内存区域是隔离的,是安全的。 这块内存区域会非常小,但是却非常关键,他的主要作用是存储一段字节码,这段字节码记录的是当前线程下一条需要执行的字节码地址。简单点说就是,记录着一个位置,这个位置就是当前线程下一次需要执行的代码位置。 然而对于一个单核cpu来说,只能同时执行一条指令,但是如何实现多线程的呢? 这时候程序计数器就会起到决定作用了。 java虚拟机的多线程是通过线程轮流切换分配处理执行时间的方式来实现的,在任何一个确定的时刻,一个处理器(对于多核处理器来说是一个内核)都只会执行一条程序中的指令。因此,为了线程切换后能恢复到正确的执行位置,每条线程都需要一个独立的程序计数器,各条线程之间计数器互不影响,独立存储。 简单点说,对于单核处理器,是通过快速切换线程执行指令来达到多线程的,真正处理器就能同时处理一条指令,只是这种切换速度很快,我们根本不会感知到。 ### 九、jvm中常见调优参数有哪些?请举例说明。 -Xms2g:初始化推大小为 2g; -Xmx2g:堆最大内存为 2g; -XX:NewRatio=4:设置年轻的和老年代的内存比例为 1:4; -XX:SurvivorRatio=8:设置新生代 Eden 和 Survivor 比例为 8:2; –XX:+UseParNewGC:指定使用 ParNew + Serial Old 垃圾回收器组合; -XX:+UseParallelOldGC:指定使用 ParNew + ParNew Old 垃圾回收器组合; -XX:+UseConcMarkSweepGC:指定使用 CMS + Serial Old 垃圾回收器组合; -XX:+PrintGC:开启打印 gc 信息; -XX:+PrintGCDetails:打印 gc 详细信息。 ## 垃圾回收部分 ### 一、如何判断一个对象应该被回收? 1.该对象没有与GC Roots相连 2.该对象没有重写finalize()方法或finalize()已经被执行过则直接回收(第一次标记)、否则将对象加入到F-Queue队列中(优先级很低的队列)在这里finalize()方法被执行,之后进行第二次标记,如果对象仍然应该被GC则GC,否则移除队列。 (在finalize方法中,对象很可能和其他 GC Roots中的某一个对象建立了关联,finalize方法只会被调用一次,且不推荐使用finalize方法) ### 二、垃圾收集算法有哪些? GC最基础的算法有三种: 标记 -清除算法、复制算法、标记-压缩算法,我们常用的垃圾回收器一般都采用分代收集算法。 - 标记 -清除算法,“标记-清除”(Mark-Sweep)算法,如它的名字一样,算法分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收掉所有被标记的对象。 - 复制算法,“复制”(Copying)的收集算法,它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。 - 标记-压缩算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。 - 分代收集算法,“分代收集”(Generational Collection)算法,把Java堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法。 ### 三、常用的垃圾回收器有哪些? 1、Serial收集器:串行收集器是最古老,最稳定以及效率高的收集器,可能会产生较长的停顿,只使用一个线程去回收。 2、ParNew收集器:ParNew收集器其实就是Serial收集器的多线程版本。 3、Parallel收集器:Parallel Scavenge收集器类似ParNew收集器,Parallel收集器更关注系统的吞吐量。 4、Parallel Old收集器:Parallel Old是Parallel Scavenge收集器的老年代版本,使用多线程和“标记-整理”算法。 5、CMS收集器:CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。 6、G1收集器:G1 (Garbage-First)是一款面向服务器的垃圾收集器,主要针对配备多颗处理器及大容量内存的机器,以极高概率满足GC停顿时间要求的同时,还具备高吞吐量性能特征。 ### 四、方法区不在堆内,会被垃圾回收吗? 在jdk1.7中,方法区在永久代,而永久代本身就是垃圾回收概念下的产物,full gc时就会对方法区回收。 到了jdk1.8,虽然永久代被取消,但是新增了MaxMetaspaceSize参数,对于将死的类及类加载器的垃圾回收将在元数据使用达到“MaxMetaspaceSize”参数的设定值时进行。 所以,方法区会被回收。 ### 五、什么叫OopMap? 在HotSpot中,虚拟机把对象内的什么偏移量上是什么类型的数据的信息存在到一个叫做“OopMap”的数据结构中。这样在计算引用链时直接查OopMap即可,不用到整个内存中去挨个找了,由此提高了分析速度。 ### 六、简单说一下java的垃圾回收机制? java采用分代回收,分为年轻代、老年代、永久代。 年轻代又分为E区、S1区、S2区。到jdk1.8,永久代被元空间取代了。 年轻代都使用复制算法,老年代的收集算法看具体用什么收集器。 默认是PS收集器,采用标记-整理算法。 ### 七、如果对象的引用被置为 null,垃圾收集器是否会立即释放对象占用的内存? 不会。 对象回收需要一个过程,这个过程中对象还能复活。而且垃圾回收具有不确定性,指不定什么时候开始回收。 ### 八、为什么要使用分代回收机制? 因为没有一种算法能适用所有场合。在对象存活率低的场景下,复制算法最合适。 对象存活率高时,标记清除或者标记整理算法最合适。 所以才需要分代来处理。 ### 九、系统为什么会频繁的full gc? full gc过于频繁有可能会造成oom,有可能不会。 full gc触发原因有很多种,但归根到底都是因为内存空间不足了(system.gc的情况不考虑)。 系统在频繁的full gc,但并没有出现oom,说明每次回收的时候,肯定清理了部分内存空间。那这里就有2种情况,gc之后清理的内存空间大不大? 1、如果每次gc之后剩余的空间不大,说明有一部分顽固对象一直没法被回收,导致可用内存变少。这种情况下很容易后续出现oom,比如说一次大对象的申请 2、如果每次gc之后剩余的空间比较大,意味着大部分对象都被清理了,但是系统又在频繁的full gc,说明很快老年代又会涌入大量对象。这个时候就应该检查下jvm的参数配置,很有可能是新生代设置的太小了,导致很多应该在minor gc阶段就清理出去的对象留到了老年代,这种可能性是最大的 新生代可以分为eden、survivor0、survivor1,正常的对象分配都是在eden完成的,如果eden空间不够了,会触发一次minor gc,存活的对象放在s0或s1中。随着每次minor gc,存活的对象会不断的从s0迁到s1,再从s1迁到s0,这个过程经过几次之后,如果对象还是存活的,就会晋升到老年代。 但如果新生代大小设置的太小,就会导致非常频繁的minor gc,s0->s1来回切换的速度加快,导致本身应该在minor gc就清理出去的对象跑到了老年代。 举个例子,正常情况下如果minor gc是1分钟一次,-XX:MaxTenuringThreshold默认配置是15的话,正常的小对象最长可以在新生代待15分钟左右,如果一个对象o的存活时间是5分钟,那它就可以在minor gc的时候被清理出去;但如果新生代设置过小,minor gc的频率降到10秒一次,那么o只能在新生代待150秒左右,然后就会晋升到老年代,这种对象一多,就会导致频繁的full gc。 ## nginx部分 ### 一、fastcgi 与 cgi 的区别? **cgi** web服务器会根据请求的内容,然后会fork一个新进程来运行外部c程序(或perl脚本), 这个进程会把处理完的数据返回给web服务器,最后web服务器把内容发送给用户,刚才fork的进程也随之退出。如果下次用户还请求改动态脚本,那么web服务器又再次fork一个新进程,周而复始的进行。 **fastcgi** web服务器收到一个请求时,他不会重新fork一个进程(因为这个进程在 web 服务器启动时就开启了,而且不会退出),web服务器直接把内容传递给这个进程(进程间通信,但fastcgi使用了别的方式,tcp方式通信),这个进程收到请求后进行处理,把结果返回给web服务器,最后自己接着等待下一个请求的到来,而不是退出。 所以区别就是**是否重复 fork 进程,处理请求。** ### 二、请列举Nginx和Apache之间的不同点 1、轻量级,同样起web服务,Nginx比Apach占用更少的内存及资源。 2、抗并发,Nginx处理请求是异步非阻塞的,而Apache则是阻塞型的,在高并发下Nginx能保持低资源低消耗高性能。 3、最核心的区别在于Apache是同步多进程模型,一个连接对应一个进程;Nginx是异步的,多个连接(万级别)可以对应一个进程。 4、Nginx高度模块化的设计,编写模块相对简单。 ### 三、nginx 如何做到高性能和高扩展的? nginx在web性能上的表现尤为出众,这完全得益于其设计方式,许多web和应用服务器都是基于线程或进程这种简单的架构,nginx用了一种精妙的事件驱动架构,在现代的硬件上,它可以处理成千上万的并发连接。他的线程模型和tomcat,netty,redis等如出一辙,都是基于事件驱动的异步非阻塞模式。 ### 四、nginx如何开启gzip实现优化? 如下配置,开启Gzip压缩优化 ```nginx server { location / { gzip on; gzip_min_length 1k; gzip_buffers 16 64k; gzip_http_version 1.1; gzip_comp_level 9; gzip_types text/plain text/javascript application/javascript image/jpeg image/gif image/png application/font-woff application/x-javascript text/css application/xml; gzip_vary on; root html/subCharge; index index.html index.htm; } ********* } ``` ### 五、nginx如何开启expires缓存实现优化? 在客户端缓存文件可以在很大程度上减轻服务器端的压力,试想如果每次请求都从服务器上获取资源,将浪费很多流量,因此我们要在客户端缓存文件。 那么,我们应该缓存什么样的文件呢? 1. 图片文件,图片文件一般相对文本文件来说都比较大,且一般不会修改。 2. css、js文件,这些文件能够独立为一个文件,相对改动的场合也较少。 3. 静态html文件,不经常改动的静态html文件也可以做为缓存对象。 缓存文件有什么缺点吗? 任何功能不可能是完美的,有优点必然也有缺点,缓存的缺点就是万一要修改缓存的文件,如果还用原来的文件名,则客户端不会重新获取服务器上的资源,看到的仍然是本地缓存的东西,因此,当要修改缓存的对象时,最好能把文件名改掉,这样客户端才会获取新的资源并且重新缓存文件。 nginx配置缓存 ```nginx location ~ .*\.(png|jpeg|jpg|gif|ico)$ { expires 30d; } ``` ### 六、nginx如何开启FastCGI参数实现优化? fastcgi配置优化如下: ```nginx fastcgi_connect_timeout 600; fastcgi_send_timeout 600; fastcgi_read_timeout 600; fastcgi_buffer_size 64k; fastcgi_buffers 4 64k; fastcgi_busy_buffers_size 128k; fastcgi_temp_file_write_size 128k; fastcgi_temp_path /usr/local/nginx1.10/nginx_tmp; fastcgi_intercept_errors on; fastcgi_cache_path /usr/local/nginx1.10/fastcgi_cache levels=1:2 keys_zone=cache_fastcgi:128minactive=1d max_size=10g; ``` **fastcgi_connect_timeout**:指定连接到后端FastCGI的超时时间,如:600 **fastcgi_send_timeout**:向FastCGI传送请求的超时时间,如:600 **fastcgi_read_timeout**:指定接收FastCGI应答的超时时间,如:600 **fastcgi_buffer_size**:指定读取FastCGI应答第一部分需要用多大的缓冲区,默认的缓冲区大小为fastcgi_buffers指令中的每块大小,可以将这个值设置更小,如: 64k。 **fastcgi_buffers**:指定本地需要用多少和多大的缓冲区来缓冲FastCGI的应答请求,如果一个php脚本所产生的页面大小为256KB,那么会分配4个64KB的缓冲区来缓存,如果页面大小大于256KB,那么大于256KB的部分会缓存到fastcgi_temp_path指定的路径中,但是这并不是好方法,因为内存中的数据处理速度要快于磁盘。一般这个值应该为站点中php脚本所产生的页面大小的中间值,如果站点大部分脚本所产生的页面大小为256KB,那么可以把这个值设置为“8 32K”、“4 64k”等。如:4 64k **fastcgi_busy_buffers_size**:建议设置为fastcgi_buffers的两倍,繁忙时候的buffer,如:128k **fastcgi_temp_file_write_size**:在写入fastcgi_temp_path时将用多大的数据块,默认值是fastcgi_buffers的两倍,该数值设置小时若负载上来时可能报502BadGateway,如:128k **fastcgi_temp_path**:缓存临时目录 **fastcgi_intercept_errors**:这个指令指定是否传递4xx和5xx错误信息到客户端,或者允许nginx使用error_page处理错误信息,如:on **fastcgi_cache_path**:如: /usr/local/nginx1.10/fastcgi_cachelevels=1:2 ### 七、nginx如何开启高效文件传输模式? 1、sendfile参数用于开启文件的高效传输模式,该参数实际上是激活了sendfile()功能,sendfile()是作用于两个文件描述符之间的数据拷贝函数,这个拷贝操作是在内核之中的,被称为 "零拷贝" ,sendfile()比read和write函数要高效得多,因为read和write函数要把数据拷贝到应用层再进行操作 2、tcp_nopush参数用于激活Linux 上的TCP_CORK socket选项,此选项仅仅当开启sendfile时才生效,tcp_nopush参数可以允许把http response header和文件的开始部分放在一个文件里发布,以减少网络报文段的数量。 相关配置如下: ```shell cat /usr/local/nginx/conf/nginx.conf ...... http { include mime.types; server_names_hash_bucket_size 512; default_type application/octet-stream; sendfile on; # 开启文件的高效传输模式 tcp_nopush on; # 激活 TCP_CORK socket 选择 tcp_nodelay on; #数据在传输的过程中不进缓存 keepalive_timeout 65; server_tokens off; include vhosts/*.conf; } ``` ### 八、Nginx如何配置防盗链? 相关配置如下: ```nginx server { listen 80; server_name www.test.com; root /data/web/; index index.php index.html; access_log /data/logs/nginx/biao.madacode.access.log main; location /{ root /home/data/; } error_page 404 /usr/local/nginx/html/404.html; ##防盗链核心配置 location ~ .*\.(wma|wmv|asf|mp3|mp4|mmf|zip|rar|jpg|gif|png|swf|flv)$ { valid_referers none blocked server_names *.test.com http://IP; if ($invalid_referer) { return 403; } expires 24h; access_log off; } location ~ /\. { deny all; } } ``` 配置说明: vaild_referers有效的引用连接,如下,否则就进入$invaild_refere,返回403 forbiden。 1、none "Referer" 来源头部为空的情况 2、blocked "Referer"来源头部不为空,但是里面的值被代理或者防火墙删除了,这些值都不以[http://或者https://开头](http://xn--https-wm6jl44o//开头). 3、server_names "Referer"来源头部包含当前的server_names(当前域名) ### 九、nginx如何优化worker进程数? Nginx有Master和worker两种进程,Master进程用于管理worker进程,worker进程用于Nginx服务, worker进程数应该设置为等于CPU的核数,高流量并发场合也可以考虑将进程数提高至CPU核数 * 2 步骤如下: 1、grep -c processor /proc/cpuinfo # 查看CPU核数 2、vi /usr/local/nginx/conf/nginx.conf # 设置worker进程数 worker_processes 2; user nginx nginx; ...... 3、检查语法,并重新加载nginx ps -ef | grep nginx | grep -v grep # 验证是否为设置的进程数